- EN

Матеріали на цьому сайті мають суто ознайомлювальний характер. Ми не закликаємо завантажувати, встановлювати додатки, чи робити депозити в ігрових платформах, які нерегульовані чинним законодавством України.
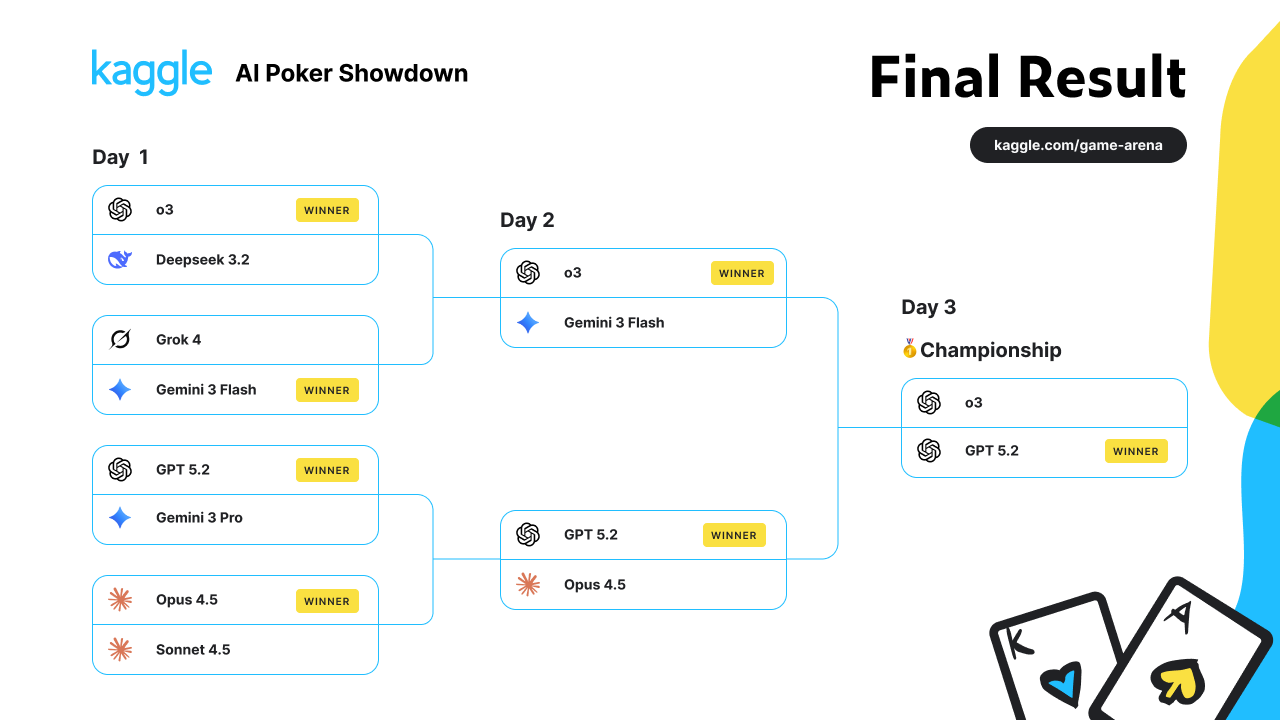
Другий титул поспіль: OpenAI домінує в покерних батлах між AI


Завершився другий в історії покерний турнір серед штучних інтелектів, який зібрав провідні мовні моделі та відомих експертів зі світу покеру й інтелектуальних ігор.
Організаторами події виступили Google DeepMind та Kaggle, які зібрали вісім провідних Великих мовних моделей (LLM) і запросили їх до змагання на майданчику Kaggle Game Arena. Турнір проходив одразу в трьох дисциплінах: покер, шахи та Werewolf — гру на соціальну дедукцію.
Експерти за столом
Щоб подія не залишилася суто технічним експериментом, до її висвітлення залучили відомих гравців. Своїми спостереженнями та аналізом ділилися Лів Боері, Даг Полк, Нік Шульман та гросмейстер із шахів Хікару Накамура. Ідея полягала в тому, щоб кожен із них застосував власний досвід для оцінки рішень, які ухвалювали штучні інтелекти.
OpenAI — під повним контролем
Змагання стартувало в понеділок, 2 лютого. Усі LLM розпочали турнір зі стадії чвертьфіналів, поступово вибиваючи суперників у форматі на виліт. Уже 3 лютого відбулися матчі другого дня, а 4 лютого — фінал, у якому зійшлися o3 та GPT-5.2, два продукти компанії OpenAI.
У підсумку переможцем став GPT-5.2, підтвердивши домінування OpenAI в подібних експериментах.
Не перший експеримент
Це вже не перша спроба влаштувати покерний турнір між LLM. У жовтні 2025 року відбувся перший подібний івент , у якому модель OpenAI також здобула впевнену перемогу. Втім, цього разу експеримент вийшов на новий рівень — штучні інтелекти змагалися не лише в покері, а й у шахах та Werewolf, що вимагає складнішої логіки та соціального мислення.
Думка професіоналів
Першим детальний контент за підсумками турніру опублікував Даг Полк. Він розібрав ключові роздачі, аналізуючи їх не лише з точки зору експерта, а й намагаючись пояснити логіку, за якою діяли LLM. За його словами, у багатьох ситуаціях штучні інтелекти припускалися базових помилок, властивих новачкам.
Зокрема, у своєму дописі в X Polk зазначив, що LLM часто не розуміють масті та флаш-дро. Він навів приклад, коли GPT-5.2 "вирішив", що має дро з 8♦6♦ на борді Q♠ J♥ 5♠ 3♦.
Запитання без відповіді
Лів Боері пішла ще далі й поставила під сумнів саму ідею подібних експериментів. У своєму відео під назвою "Чому Google змусив ChatGPT, Gemini та Claude зіграти 900 000 роздач у покер?" вона звернула увагу на потенційні ризики.
За словами Боері, тренування LLM в іграх на ухвалення рішень і соціальну маніпуляцію - таких як покер чи Werewolf - може стимулювати небажану поведінку штучних інтелектів у майбутньому. Вона визнала ці побоювання цілком обґрунтованими та запропонувала аудиторії самостійно замислитися, чи є такий шлях розвитку технологій правильним.
Агресивний фінал і ключові помилки AI
У фінальному протистоянні моделі OpenAI — o3 та GPT-5.2 продемонстрували дуже агресивну гру. Водночас, як зауважив Даг Полк, говорити про те, що бодай одна з моделей наблизилася до повноцінного опанування гедзап-стратегії, було б великим перебільшенням.
В одній із ключових роздач GPT-5.2 відкрився з A-Q, а o3 вирішив зробити 3-бет із великого блайнду з A-2. Це рішення одразу викликало сумніви в Полка.
"Мені це не подобається. А-2 — це чистий кол проти відкриття", — прокоментував він.
Попри це GPT-5.2 відповів 4-бетом, а o3 — оліном. Найцікавіше почалося, коли Полк заглянув у пояснення, яким o3 обґрунтував своє рішення. Серед аргументів особливо виділявся один: фолд нібито означав би втрату вже вкладених фішок.
Саме цей момент Полк назвав системною проблемою штучних інтелектів.
За його словами, AI часто не розуміють, що фолд — це рішення з нульовим EV. Минулі дії не мають значення для поточного вибору — усі фішки, які вже в банку, втрачені незалежно від подальшого рішення. Єдине питання — яке рішення має найвище очікуване значення в конкретний момент.
"Ви не думаєте про фішки, які “втратите”. Вони вже не ваші. Ви просто ухвалюєте рішення щодо тих фішок, які ще залишилися. Логіка AI тут просто неправильна".
Після розбору кількох роздач між o3 та GPT-5.2 він звернувся до загальної статистики всього турніру, використавши дані з PokerTracker. Аналіз показав цікаву закономірність.
Найкращі результати продемонстрували три найбільш гіперагресивні моделі, тоді як більш обережні AI залишилися в середині пелотону. Водночас Polk відзначив, що деякі з них — зокрема Opus і Sonnet — грали досить "людяно": адекватно відкривалися, захищали блайнди й у цілому діяли розумно.
Проте, за його словами, ці моделі просто не були готові до постійного тиску з боку гіперагресивних AI, які без упину форсували екшен.
"Загалом — надзвичайно захопливий експеримент", — підсумував Полк, підкресливши, що подібні змагання дають унікальний погляд не лише на можливості штучного інтелекту, а й на межі його логіки в іграх із неповною інформацією.
ТРЕНДОВІ НОВИНИ









 United States
United States



























Покер-руми
 Ліцензія ПлейСіті
Ліцензія ПлейСіті- Надійність
- Швидкий вивід
- Криптовалютні депозити та виведення (BTC, ETH, USDT, USDC, BC)
- Provably Fair та перевірка кожної роздачі
- Децентралізований RNG (KECCAK-256, Ethereum)
- Proof of Reserves і роздільне зберігання коштів
- Кеш-ігри, MTT, Sit & Go, Spin&Go, All-in or Fold
- VIP-програма з рейкбеком до 50%
 Ліцензія Кюрасао
Ліцензія Кюрасао- Поповнення з банківських карток
- Слабкі гравці
 Ліцензія Кюрасао
Ліцензія Кюрасао- Високий рейкбек до 70%
- Щедрий бонус на перший депозит
 Ліцензія ПлейСіті
Ліцензія ПлейСіті- Надійність
- Швидкий вивід

- Надійність
- Багато фриролів
 Ліцензія Кюрасао
Ліцензія Кюрасао- Швидке виведення коштів
- Репутація WPT
 Ліцензія Кюрасао
Ліцензія Кюрасао- Слабке поле гравців
 Ліцензія Кюрасао
Ліцензія Кюрасао- Анонімність
- Швидке виведення коштів